Tag 1
Linux – Debian – Ubuntu
Zum Start haben wir den Horizon Client installiert, um Zugriff auf die Virtuelle Maschine zu erhalten. Wir werden über das Semester alle mit Ubuntu, Version 20.04 LTS arbeiten. LTS steht für Long Term Support, das heisst diese Versionen werden längerfristig unterstützt und im Zweijahresrhythmus aktualisiert. 20.04 steht hier für April 2020. Im April erscheinen jeweils die neuen Versionen. Ubuntu basiert auf der Debian-Architektur auf und wird vom Grossteil der Privatpersonen genutzt. Es ist ein sogenanntes Derivat, Architektur und Infrastruktur werden also von Debian übernommen, daraus wird aber ein eigenes Betriebssystem aufgebaut. Debian hingegen ist eine GNU/Linux-Distribution, die seit 1996 auf dem Markt ist. Wir könnten anstelle von Linux auch mit Debian arbeiten, für uns als Klasse wäre das aber schnell überfordernd. Debian ist für professionelle Anwender*innen geeignet. Eine GNU/Linux-Distribution ist schlussendlich, was von den meisten schlicht “Linux” genannt wird und aus zwei wesentlichen Teilen besteht: Einem Linux-Kernel und dem früheren Standardsystem Unix, welches im Gegensatz zu Linux kommerziell ist. Linux hingegen ist Open Source und hat seinen Namen von Linus Torvalds (und Unix).
Lerninhalte des Moduls
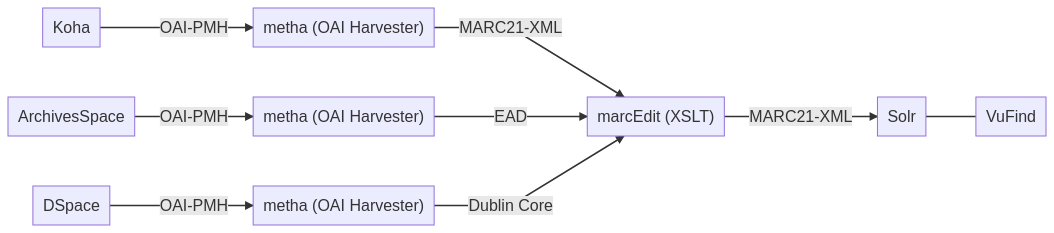
Diese Übersicht zeigt, was wir in diesem Kurs vorhaben. Die Daten kommen aus den Systemen Koha (Bibliotheken), Archivespace (Archive) und DSpace (Dokumentenablage für Publikationen und Forschungsdaten). Anschliessend dient die Schnittstelle OAI-PMH (OAI Protocol for Metadata Harvesting) dem Einsammeln und Weiterverarbeiten von Metadaten. Mit dem “metha-command” werden die Informationen inkrementell an den OAI-PMH-Endpunkten gesammelt. Die Daten aus den folgenden Systemen sind nach dem Export in unterschiedlichen Formaten vorhanden:
Koha – MARC21-XML
ArchiveSpace – EAD (ebenfalls ein XML-Format)
DSpace – Dublin Core
Anschliessend müssen diese Dateiformate vereinheitlicht werden, um eine ideale gemeinsame Verarbeitung, beziehungsweise einen Austausch zu ermöglichen. Dies geschieht mit der Metadatenverarbeitungssoftware MarcEdit, welche dafür sorgen soll, dass schlussendlich alle Dateien im bibliographischen Datenformat MARC21-XML abgespeichert sind.
Schlussendlich können die Daten über die Suchmaschine Solr abgerufen werden. Solr ist eine horizontale Suchmaschine. Das bedeutet, dass die Daten, die abgerufen werden können, alle auf eine Domain, ein bestimmtes Thema oder eine Zielgruppe abgestimmt sind. Sie ist also thematisch ausgerichtet. Nur die von uns eingespeisten Datensätze werden abrufbar sein. Da Solr aber keine einfach handzuhabende Suchoberfläche bietet, wird für die Suche das Discovery-System VuFind verwendet. VuFind wurde gemacht, um eine nutzerfreundliche Suchoberfläche zur Suchmaschine Solr zu gewährleisten. Dadurch wird allen Nutzer*innen die Möglichkeit gegeben, Suchanfragen abzuschicken.
Alle in der Grafik zu sehenden Softwares sind Open Source – die Metadaten sollen frei weitergegeben werden können. Wie bereits erwähnt finde ich diesen Ansatz sehr gut.
GitHub
Zum Schluss hatte ich noch ziemlich grosse Probleme mit GitHub, da ich die auf der Webseite die Dateien nicht verschieben und die Ordner nicht umbenennen oder löschen konnte. Daraufhin habe ich mit “git init” und “git pull https://github.com/remooda/bain.git” das Verzeichnis auf meinen Mac gezogen und bearbeitet. Ich konnte nun die Dateien nach Belieben bearbeiten und habe versucht, mit “git push –set-upstream bain master” das Verzeichnis wieder raufzuladen. Leider hat die Synchronisierung nicht funktioniert, anscheinend war sowohl bei “git push” als auch bei “git pull” alles “up to date”, obwohl die Verzeichnisse auf GitHub und auf meinem Rechner nicht miteinander übereinstimmen. Für einen neuen ssh-clone hatte ich die Rechte dazu nicht.
Als letzten Versuch habe ich den clone nicht über ssh sondern über https gemacht. Da ich keine ssh-keys registriert habe, hat der clone über ssh nicht funktioniert. Mit https hat es nun geklappt und ich konnte die Konfiguration abschliessen.
Bilder laden
Zu guter letzt kommt noch ein weiteres Problem. Die Bilder werden nicht geladen. Genauer gesagt, auf “github.com”, wo ich die Dateien momentan bearbeite, klappt es. Auf “github.io”, wo die User auf meine Blogbeiträge gehen, wird nur der alternative Text angezeigt. GitHub-Pages sind case sensitive, doch auch bei korrekter Gross- und Kleinschreibung klappt es nicht. Auch beim Versuch, anstelle eines PNGs ein JPG zu verwenden, kann das Bild nicht auf “github.io” angezeigt werden.
Der Fehler lag schlussendlich ganz woanders, fälschlicherweise habe ich folgendes Format verwendet:
<img src="../pictures/1.png" alt="Logo">
Mit diesem Format konnte das Bild im GitHub-Branch angezeigt werden, jedoch nicht auf dem tatsächlichen Blog. Mit dem folgenden von Felix Lohmeier empfohlenen Format klappt es nun:
