Tag 9
Inputs
Wir haben noch einen kurzen Nachtrag zu LIDO erhalten: Der Standard ist echt gut und die ungewohnte Struktur soll nicht abschreckend wirken. Für Crosswalks gibt es – wie wir es schon kennen – Mapping-Dateien, wie zum Beispiel die folgende Excel-Datei:
https://www.smb.museum/fileadmin/website/Institute/Institut_fuer_Museumsforschung/Fachstelle_Museum/DDB-LIDO_1.9.xlsx
Auch zu Solr gab es noch einen kurzen Input: Wie bereits erwähnt ist Solr zusammen mit Elasticsearch die meistgenutzte Suchmaschine. Auch z.B. Ex Libris Primo nutzt Solr. Eine wirklich brauchbare Suchoberfläche wird bei Solr aber leider nicht mitgeliefert. Dafür braucht man beispielsweise das Discovery-System VuFind, was wir ja auch machen.
Die Solr-Administrationsoberfläche ist auf Port 8983, dort können viele Einstellungen angepasst werden. Es kann vorkommen, dass der Port nicht erreichbar ist. In diesem Falle muss wahrscheinlich Solr nochmals gestartet werden. Dies geht wie folgt:
cd /usr/local/vufind/
./solr.sh start
Unterschied von Suchindex und Datenbank
Anstelle einer relationalen Datenbank nutzt die Suchmaschine Solr einen Suchindex. Wir haben uns die zentralen Unterschiede angeschaut.
Suchindex (Solr)
In einem Suchindex wie Solr sind Dokumente abgespeichert. Die Datenverarbeitung ist nicht oder nur schwer möglich. Trunkierung und simple Textsuche ist möglich, komplexe Suchanfragen aber nicht. Für komplexe Suchanfragen werden Datenbanken wie MySQL empfohlen. Da die suche lexikalisch ist und keine Konsistenzprüfung gemacht wird, können auch ähnlich geschriebene Suchergebnisse erscheinen und es ist kein klassischer 1:1-Abgleich.
–> ist hauptsächlich für die Suche (Retrieval) geeignet
Datenbank (MySQL)
Bei Datenbanken wie MySQL geschieht hingegen ein 1:1-Abruf von eingegebenen Termen – also ein reiner Glyphenvergleich. Dies führt zu weniger guten Resultaten (ausser man will explizit eine exakte Suche, was aber in der Praxis selten vorkommt). MySQL funktioniert nach dem CRUD-Ansatz, das bedeutet “Create, Read, Update, Delete”. Datensätze werden also persistent und konsistent abgespeichert und können anschliessend verwaltet werden. Dies beinhaltet lesen, updaten und/oder löschen.
–> ist hauptsächlich fürs abspeichern von Daten (Storage) geeignet.
VuFind
Kommen wir wieder zurück zu VuFind: Nach der Installation gibt es verschiedene Dateien, welche angepasst werden können, um die Einstellungen von VuFind anzupassen. Eine genauere Anleitung ist hier zu finden. Hier gehe ich kurz auf die wichtigsten Dateien ein.
searches.ini
Hier wird z.B. eingestellt, ob die Suchergebnisse nach Relevanz oder Alphabet sortiert werden. Es können die Suchanfragen- und Sortierungsoptionen bearbeitet werden. Auch die Vorschläge, die erscheinen, wenn keine Suchresultate vorhanden sind, können angepasst werden. Ebenfalls hier zu finden ist die Einstellung zum Autocomplete vom Suchfeld.
facets.ini
Hier werden die Filter bearbeitet. Durch die Filter können die Suchresultate eingeschränkt werden und ich empfinde es als ziemlich wichtig, dass bei einer Suchmaschine sinnvolle Filter vorhanden sind.
searchspecs.yml
In dieser Datei wird die Relevanz/Gewichtung der verschiedenen Felder angepasst. Beispielsweise kann das Feld “Titel” doppelt so hoch gewichtet werden, wie das Feld “Autor*in*. Dies würde dazu führen, dass Bücher über eine bestimmte Person viel relevanter gerankt werden, als Bücher von einer bestimmten Person (sofern ihr Name im Titel vorkommt). In der folgenden Übung wird noch genauer auf die Gewichtung eingegangen.
Suche in VuFind vs. Suche in Solr
In dieser Übung haben wir zuerst eine Suche in VuFind und anschliessend eine Suche über die Solr-Administrationsoberfläche auf dem VuFind-Port gemacht. Während den Suchanfragen haben wir die Logdatei von Solr im Terminal betrachtet. Dies ist mit folgendem Terminal-Befehl möglich:
less +F /usr/local/vufind/solr/vufind/logs/solr.log
Die Logdatei aus der Suche mit VuFind gibt deutlich ausführlichere Infos. Der hier markierte Teil ist ein Ausschnitt daraus:
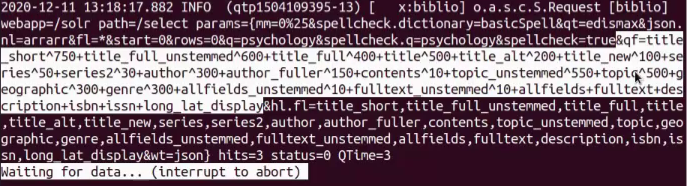
Bei diesem Log sieht man die Gewichtung der einzelnen Felder. Jedes Feld wird mit einer bestimmten Zahl multipliziert, welche die Gewichtung angibt. Diese wurde zuvor in der Datei “searchspecs.yml” festgelegt, welche unter “Computer/usr/local/vufind/config/vufind” abgelegt ist.
Mein wichtigstes Learning: Der Suchalgorithmus eines Discovery-Systems ist gar nicht so komplex konfiguriert, wie ich zu beginn dachte. Es basiert meist nur auf einer Gewichtung der einzelnen Felder.
In der Praxis muss man also diese Felder gewichten. Für diese Feinjustierung des Algorithmus muss man:
- die Hauptnutzungsgruppen suchen
- herausfinden, welche Suchanfragen wohl am meisten getätigt werden
- Gewichtung ausprobieren (für VuFind in der Datei “searchspecs.yml”)
- schauen, welche Gewichtung die besten Resultate bringt und stetig anpassen, bis man mit den Ergebnissen zufrieden ist
Übung Import in Solr
Nun kommen wir zur Übung, auf die wir schon lange warten und viele Vorbereitungen dafür getroffen haben: Die Dateien, die wir aus ArcivesSpace, DSpace und Koha exportiert haben, sollen von uns in die Suchmaschine Solr eingespielt werden. Zuerst wird der folgende Befehl ausgeführt und anschliessend die angesteuerte Datei “marc_local.properties” angepasst:
gedit /usr/local/vufind/import/marc_local.properties
Im Dokument “marc_local.properties” muss bei den unten abgebildeten drei auskommentierten Zeilen die Raute wieder entfernt werden:
collection = “ArchivesSpace”
institution = “Name der Institution”
building = “Bibliothek A”
Dies dient dazu, den verschiedenen Datenquellen eine collection zuzuweisen und sie so identifizierbar zu machen.
Mit dem folgenden Befehl werden nun alle vorbereiteten XML-Dateien, die aus Koha gekommen sind und im Ordner Koha abgelegt sind, importiert.
for f in ~/koha/*.xml; do /usr/local/vufind/import-marc.sh $f; done
Dasselbe wird anschliessend für die anderen Ordner mit zu importierenden XML-Dateien gemacht (für und ArchivesSpace und DSpace).
Bei unserem Import ist gleich ein Fehler aufgetreten:
VuFind nutzt das MARC-Feld 001 als ID. Wenn die Datei das Feld 001 nicht hat, klappt der Import nicht. Ich kann mir gut vorstellen, dass dieser Fehler öfters passiert. Im Datenstrukturierungskurs an der HAW Hamburg haben wir beispielsweise nicht gelernt, dass das Feld 001 ausgefüllt werden muss. Falls ich jedenfalls mal an dem Punkt ankomme, dass ich viele Dateien ohne Feld 001 vor mir habe und diese alle in VuFind importieren muss, würde ich dafür OpenRefine verwenden. So könnte ich das Feld bei allen Dateien auf einmal vergeben.
Abgesehen von dieser Fehlermeldung hat alles reibungslos funktioniert und damit ist unser “Hauptkursziel” eigentlich schon erreicht :)