Abschlussartikel
Nun sind wir am Ende des Kurses angelangt. Anhand der Kursübersicht möchte ich die zentralen Inhalte nochmals Revue passieren lassen
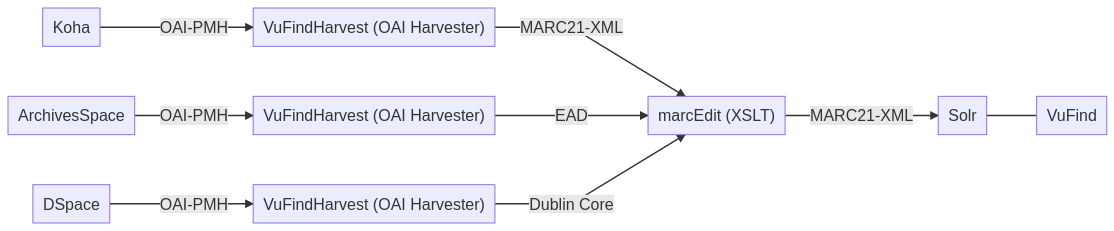
Zu Beginn haben die Systeme Koha (Bibliotheken), Archivespace (Archive) und DSpace (Publikationen und Forschungsdaten) kennengelernt:
Koha fand ich ein sehr übersichtliches Bibliothekssystem. Ausleihe, Rückgabe und Medienerfassung funktionieren sehr schnell. Die Funktion, Katalogisate über das Netzwerkprotokoll Z39.50 zu importieren, ist sehr nützlich.
ArchivesSpace fand ich schon weniger einfach handzuhaben. Der Import der Datensätze hat nicht ideal funktioniert. Ich habe aber auch grundsätzlich weniger Erfahrung mit Archiven und Archivprogrammen als mit Bibliotheken und deren Softwares.
DSpace habe ich immer noch nicht ganz verstanden. Es wäre gut gewesen, mehr Zeit zu investieren und sich zusammen mit den Dozierenden einen Überblick zu verschaffen. Da ich noch nie mit einem Repository für Publikationen und Forschungsdaten gearbeitet habe, ist es auch verständlich, dass ich damit Mühe hatte.
Über die Schnittstelle OAI-PMH haben wie die gewonnenen Metadaten eingesammelt und weiterverarbeitet. Für das Einsammeln haben wir einen sogenannten OAI-Harvester genutzt, das war VuFindHarvest. Das Harvesting wurde über die Kommandozeile gemacht und war nicht einfach. Dafür waren die Befehle sehr kurz und wer weiss wie es funktioniert, wird mit dem Harvesting auch schnell fertig sein. Das ganze Harvesting war nur möglich, weil bei allen drei Programmen sogenannte “OAI-PMH-Endpoints” verfügbar waren. Das ist ein grosser Pluspunkt für Koha, ArchivesSpace und DSpace.
Nach dem Harvesting haben wir einen XSLT-Crosswalk mit MarcEdit gemacht, damit die Dateien alle im selben Format sind. MarcEdit fand ich ein sehr mühsames Programm mit veraltetem Design. Auch die Usability ist aus meiner Sicht nicht ideal. Immerhin hat das Mapping von den Ausgangsformaten (EAD und Dublin Core) zum Endformat (MARC21-XML) funktioniert. Gute Alternativen zum Programm gibt es leider fast keine. Eine haben wir aber angeschaut: OpenRefine. Ich finde das Programm sehr gut und (nach einer gewissen Einarbeitung) einfach zu handhaben. Das Programm bietet viele Möglichkeiten im Bereich Datenbereinigung, -analyse und -transformation. Die Massenbearbeitung von Tabellen funktioniert schnell. Die vielen Möglichkeiten führen aber auch dazu, dass man sich deutlich länger einarbeiten muss, um einen Crosswalk vom einen Format ins andere durchzuführen.
Zum Schluss haben wir die Daten in den Suchindex Solr eingespielt. Mit dem Discovery-System VuFind haben wir die Datensätze schliesslich abrufen können. Ich hatte stets Schwierigkeiten, zu unterscheiden, wie sich Solr und VuFind unterscheiden und was wofür zuständig ist. Darum wollte ich die Thematik zum Abschluss nochmals genauer unter die Lupe nehmen: VuFind basiert komplett auf der Suchmaschine Solr. Da Solr aber kein nutzerfreundliches Frontend hat, wurde VuFind überhaupt erst programmiert. Dank der Installation von VuFind hatten wir eine übersichtliche Suchoberfläche zur Verfügung. Suchanfragen sind zwar auch über Solr möglich. Wenn aber eine Suchmaschine für ein breites Publikum wie z.B. in einer Bibliothek angeboten wird, ist es wichtig, eine nutzerfreundliche Suchoberfläche wie die von VuFind bereitzustellen.
Die einzigen kleinen Lücken, die am Ende des Kurses noch offen bleiben sind die Handhabung von ArchivesSpace und DSpace. Mit ArchivesSpace bin ich wohl nicht warm geworden, weil ich die ganze Struktur von Archiven immer noch nicht gut kenne und mir die Praxis damit fehlt. Bei DSpace liegt es daran, dass wir es nur sehr kurz angeschaut haben. Die gesteckten Lernziele sind aus meiner Sicht aber erfüllt worden und ich bin sehr zufrieden mit dem Kurs. Ich danke Sebastian Meyer und Felix Lohmeier für die vielen verschiedenen Inputs und bin gespannt darauf, meine Kurserkenntnisse in der Praxis anwenden zu können.